¿Cómo sabe YouTube lo que quiero ver?

En este episodio hablamos sobre sistemas de recomendación, qué son, cómo funcionan y cómo YouTube y Spotify pueden recomendarnos contenido que nos interesa entre los millones de videos y canciones que tienen en su catálogo.
¿Qué es un sistema de recomendación?
Un sistema de recomendación es una herramienta que establece un conjunto de criterios y valoraciones sobre los datos de los usuarios para realizar predicciones sobre recomendaciones de elementos que puedan ser de utilidad o valor para el usuario. Estos sistemas seleccionan datos proporcionados por el usuario de forma directa o indirecta, y procede a analizar y procesar información del historial del usuario para transformar estos datos en conocimiento de recomendación.
Vamos a explicarlo con un ejemplo. Un “recomendador” es un sistema que selecciona un producto que, si se compra, maximiza el valor tanto para el comprador como para el vendedor en un determinado momento del tiempo. Para hacer las recomendaciones, el sistema analiza y procesa información histórica de los usuarios (edad, compras previas, calificaciones…), de los productos o de los contenidos (marcas, modelos, precios, contenidos similares…) y la transforma en conocimiento accionable, es decir, predice qué producto puede ser interesante para el usuario y para la empresa. Los recomendadores, además, tienen cierto nivel de autonomía a la hora de presentar las recomendaciones al usuario final.
Desde un punto de vista más técnico, los recomendadores habitualmente son de dos tipos: los filtros colaborativos y los filtros basados en contenido. En este contexto, un filtro es el algoritmo matemático que “decide” cuál es la recomendación óptima basado en los datos que le entreguemos.
Los filtros colaborativos (collaborative filtering)
Los filtros colaborativos generalmente basan su lógica en las características del usuario. Los datos que se tienen del usuario se convierten en el centro de un filtro colaborativo. El sistema analiza las compras anteriores, las preferencias, las calificaciones que ha dado de otros productos, el importe medio de las compras, etc. y busca otros usuarios que se parecen a él y que han tomado decisiones parecidas. Los productos que han tenido éxito con usuarios similares, seguramente también le interesarán al nuevo usuario. Uno de los pioneros en utilizar este tipo de filtrado fue Netflix.
Los filtros basados en contenido (content-based filtering)
Los filtros basados en contenido tienen el producto como base de la predicción, en lugar de tener al usuario. Es decir, utiliza las características del artículo (marca, precio, calificaciones, tamaño, categoría, etc.) para hacer las recomendaciones.
El problema del cómputo

Para nosotros los humanos, recomendar cosas nos resulta natural. Tenemos una intuición para recomendar películas, series, libros, juegos, etc… Cuando alguien nos cuenta que vió Terminator 1 y le encantó, nuestro cerebro rápidamente puede pensar en decirle ¿Viste Terminator 2? Te la recomiendo si te gustó la 1. ¿Por qué para una computadora no es tan trivial como para nosotros encontrar la película más parecida? ¿No se supone que las computadoras son rapidísimas? ¿Cuánto tiempo le puede tomar a una computadora darse cuenta que Terminator 2 es similar a Terminator 1? El problema está en que si la computadora intenta buscar la película más similar a Terminator 1 va a tener que comprar Terminator 1 con todas las películas que conoce. Supongamos que la computadora conoce 5 películas nomás: Terminator 1, Terminator 2, Conan, Los 101 dálmatas y Volver al futuro.Para encontrar la película más parecida a Terminator 1 va a tener que compararla contra todas las demás, es decir contra 4 películas más. Pero también voy a tener que calcular la similitud entre Terminator 2 y Conan, y los 101 dálmatas y volver al futuro, por si me preguntan por una parecida a Terminator 2. En definitiva, va a tener que calcular la similitud de todas contra todas, es decir (5^2 – 5)/2 = 10 similitudes. No son tantas. Pero qué pasa si tengo ahora 100 películas, la cantidad de similitudes que tiene que calcular son (100^2 – 100) / 2, es decir 4950, ahora Spotify tiene 82 millones de canciones en su base de datos, calcular la similitud entre todas ellas equivaldría a 3,361,999,959,000,000 cuentas (algo así como 3 mil billones de cuentas?). Esta es una de las razones por las que existen distintos enfoques para el problema recomendación.
Youtube: Content Based Filtering y la brujería del Collaborative Filtering
El trabajo entonces no es para nada sencillo pero tiene bastantes años de investigación encima. y eso permitió llegar a algunos enfoques prácticos para encarar el problema. Pero por muy variados o complejos que resulten estos algoritmos, los podemos dividir en dos grandes grupos: Content Based Filtering y Collaborative Filtering.
Supongamos que somos el trabajador de la tienda de ropa y viene nuestro cliente de siempre, Juan. Juan lleva años yendo a la misma tienda y por suerte conocemos sus gustos, a él le gustan los colores vivos, las telas suaves y estar más o menos al día con la moda actual. ¿Qué es lo más natural que podemos hacer con esa información de la ropa que le gusta a Juan? Lo más natural es seleccionar (o filtrar) aquellas prendas que tienen características parecidas; vamos a recomendarle a Juan remeras con colores vivos, pantalones modernos y quizás algún que otro accesorio complementario que esté de moda. Este tipo de forma de recomendar es el primero que surgió y se llama Content Based Filtering, básicamente porque usa las características del contenido (prendas, películas, autos, etc…) para recomendar.
Pero como vendedor podría usar la estrategia del Collaborative Filtering para recomendarle prendas a Juan. Esta estrategia puede ser un poco más arriesgada, pero en algunos contextos resultó ser muy útil. Como vendedor, podríamos saber que Juan compró anteriormente los pantalones A y B, la remera C y las zapatillas D, y que otro cliente Pepe también compró los pantalones A y B, la remera C, las zapatillas D pero también compró (y le encantó) la remera E. ¿No sería interesante mostrarle a Juan la remera E a ver si le gusta? La idea central del Collaborative Filtering es tratar de recomendar a partir de la data del usuario en vez de a partir de la data del artículo a recomendar, y por data nos referimos especialmente a la información de los gustos del usuario.
Este método me parece especialmente interesante. De alguna manera, el vendedor confía en el gusto colectivo por sobre lo que él sabe del artículo a vender. Pasamos de “Estas zapatillas son de cuero de excelente calidad y de la marca que te gusta” a “A la gente que compra parecido a vos por alguna razón que no me importa le suelen gustar estas zapatillas”. La segunda estrategia confía en una sabiduría colectiva y ni se gasta en entenderla, sólo surfearla y aprovecharla de la mejor manera posible.

Pero en el caso de Youtube, ¿qué significa que a alguien le guste un video? Por suerte cuando abrimos un video tenemos un botoncito de Me Gusta y otro de No me Gusta, que sirven únicamente para que el sistema de recomendación aprenda lo que nos interesa y lo que no. Este tipo de retroalimentación que nosotros le damos al sistema es explícita, nosotros deliberadamente le damos un mensaje claro al recomendador de que ese video nos gustó o no nos gustó, pero el sistema también usa otra información de tipo implícita como los clicks, si el video lo vimos en su totalidad, o si lo compartimos a otros usuarios. Esta información también es usada por el recomendador para aprender sobre lo que nos gusta ver y lo que no.
¿Cómo personaliza las recomendaciones?
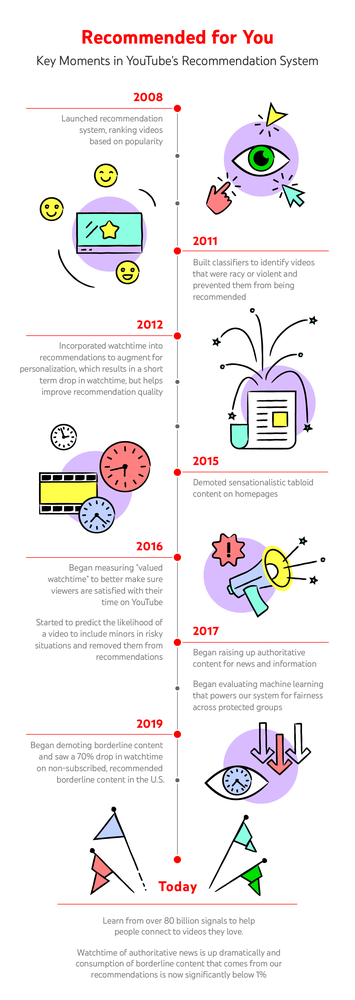
Para proporcionar tal selección personalizada, el sistema de recomendación no funciona a partir de un «libro de recetas» de qué hacer. Está en constante evolución, aprendiendo todos los días de más de 80 mil millones de piezas de información que llamamos señales. Varias señales se complementan entre sí para ayudar a informar a nuestro sistema sobre lo que te satisface: clics, tiempo de visualización, respuestas a encuestas, lo compartido, los me gusta y los no me gusta.
- Clics: hacer clic en un video proporciona una fuerte indicación de que también lo encontrarás satisfactorio. Después de todo, no harías clic en algo que no quieras ver.
Hacer clic en un video no significa que realmente lo hayas visto. Digamos que estabas buscando lo más destacado del partido de Wimbledon de ese año. Te desplazas por la página y haces clic en uno de los videos, que tiene una miniatura y un título que sugiere que muestra imágenes del partido. En cambio, se trata de una persona en su habitación hablando sobre el partido. Haces clic en un video que el sistema recomienda en tu panel “A continuación”, sólo para encontrar a otro fan hablando sobre el partido. Una y otra vez haces clic en estos videos hasta que finalmente se te recomienda un video con imágenes del partido que deseas ver. Es por eso que se agregó el tiempo de visualización en 2012. - Tiempo de visualización: el tiempo de visualización (qué vídeos miraste y durante cuánto tiempo) proporciona señales personalizadas al sistema sobre lo que probablemente quieras ver. Entonces, si un fanático del tenis vio 20 minutos de clips de momentos destacados de Wimbledon y sólo unos segundos de video de análisis de partidos, se puede asumir con seguridad que encontró más valioso ver esos momentos destacados.
Cuando incorporaron por primera vez el tiempo de visualización en las recomendaciones, vieron una caída inmediata del 20% en las visualizaciones. No todo el tiempo de visualización es igual. - Respuestas a encuestas: para asegurarse realmente de que los espectadores estén satisfechos con el contenido que miran, miden lo que llaman «tiempo de visualización de valor»: el tiempo que dedicas a ver un video que consideras valioso. Miden el tiempo de visualización de valor a través de encuestas de usuario que te piden que califiques el video que viste con una a cinco estrellas, lo que brinda una métrica para determinar qué tan satisfactorio te pareció el contenido. Si calificas un video con una o dos estrellas, te preguntan por qué le diste una calificación tan baja. De manera similar, si le das al video de cuatro a cinco estrellas, te preguntan por qué, es decir, ¿fue inspirador o significativo? Solo los videos que calificas con cuatro o cinco estrellas se cuentan como tiempo de visualización de valor. Por supuesto, no todos responden una encuesta en cada video que ven. Con base en las respuestas obtenidas, han entrenado un modelo de aprendizaje automático para predecir las posibles respuestas a la encuesta para todos. Para probar la precisión de estas predicciones, deliberadamente no usan algunas de las respuestas a la encuesta en el aprendizaje. De esta manera, siempre están monitoreando qué tanto se acerca nuestro sistema a las respuestas reales.
- Lo compartido, los me gusta y los no me gusta: en promedio, es más probable que las personas se sientan satisfechas con los videos que comparten o que les gustan. El sistema utiliza esta información para tratar de predecir la probabilidad de que compartas o te gusten más videos. Si no te gusta un video, es una señal de que probablemente no fue algo que disfrutaste viendo.

Sin embargo, al igual que tus recomendaciones, la importancia de cada señal depende de ti. Si eres el tipo de persona que comparte cualquier video que mira, incluidos los que calificas con una o dos estrellas, el sistema sabrá que no debe tomar tanto en cuenta tus acciones al recomendar contenido.
Los clics, las visualizaciones, el tiempo de visualización, las encuestas a usuarios, lo compartido, los me gusta y los no me gusta funcionan muy bien para generar recomendaciones sobre temas como música y entretenimiento, lo que la mayoría de la gente viene a ver a YouTube. Pero a lo largo de los años, un número creciente de espectadores ha recurrido a YouTube en busca de noticias e información. Ya se trate de las noticias de última hora o de estudios científicos complejos, estos temas son para los que más importa la calidad de la información y el contexto. Alguien puede informar que está muy satisfecho con los videos que afirman que “la Tierra es plana”, pero eso no significa que se quiera recomendar este tipo de contenido de baja calidad.
¿Cómo funciona el algoritmo de Spotify?

Spotify no usa un único modelo de recomendación. En su lugar, combinan algunas de las mejores estrategias utilizadas por otros servicios para crear su propio motor de descubrimiento único y poderoso.
Para crear Discover Weekly, hay tres tipos principales de modelos de recomendación que emplea Spotify:
Modelos de filtrado colaborativo (es decir, los que Last.fm usó originalmente), que analizan su comportamiento y el comportamiento de los demás.
A diferencia de Netflix, Spotify no tiene un sistema basado en estrellas con el que los usuarios califiquen su música. En cambio, los datos de Spotify son retroalimentación implícita, específicamente, la cantidad de pistas y los datos de transmisión adicionales, como por ejemplo, si un usuario guardó la pista en su propia lista de reproducción o visitó la página del artista después de escuchar una canción.
Pero, ¿qué es realmente el filtrado colaborativo y cómo funciona? Aquí hay un resumen de alto nivel, explicado en una conversación rápida:
«¡Ey, me gustan las pistas P, Q, R y S!»
«¡Bueno, a mí me encantan Q, R, S y T!»
«¡Entonces deberías escuchar P ya mismo!»
«¡Ok, y tú deberías escuchar Q!
¿Qué está pasando aquí? Cada uno de estos individuos tiene preferencias de pistas: la de la izquierda le gusta a las pistas P, Q, R y S, mientras que la de la derecha le gusta a las pistas Q, R, S y T.
El filtrado colaborativo luego usa esos datos para decir:
«Hmmm … A los dos les gustan tres de las mismas pistas, Q, R y S, por lo que probablemente sean usuarios similares. Por lo tanto, es probable que cada uno disfrute de otras pistas que la otra persona ha escuchado, que aún no ha escuchado”.
Por lo tanto, sugiere que el que está en la pista de salida P de la derecha – la única pista no mencionada, pero que disfrutó de su contraparte «similar» – y el de la pista de salida T de la izquierda, por el mismo razonamiento.
Pero… ¿Cómo utiliza Spotify ese concepto en la práctica para calcular las pistas sugeridas por millones de usuarios en función de las preferencias de millones de otros usuarios?
Con matemáticas, hecho con bibliotecas de Python

En realidad, esta matriz que ves aquí es gigantesca. Cada fila representa uno de los 140 millones de usuarios de Spotify (si usas Spotify, tú mismo eres una fila en esta matriz) y cada columna representa una de las 30 millones de canciones en la base de datos de Spotify.
Después, la biblioteca de Python ejecuta esta fórmula de factorización de matriz larga y complicada:

Cuando termina, terminamos con dos tipos de vectores, representados aquí por X e Y. X es el vector usuario, que representa el gusto de un solo usuario, e Y es un vector de canción, que representa el perfil de una sola canción.
Ahora tenemos 140 millones de vectores de usuario y 30 millones de vectores de canciones. El contenido real de estos vectores es solo un montón de números que esencialmente no tienen significado por sí mismos, pero son enormemente útiles cuando se comparan.
Para saber qué gustos musicales de los usuarios son más similares a los nuestros, el filtrado colaborativo compara nuestro vector con todos los vectores de los demás usuarios, y finalmente revela qué usuarios son los más cercanos. Lo mismo ocurre con el vector Y, canciones: puede comparar el vector de una sola canción con todos los demás, y descubrir qué canciones son más similares a la que se trata.

Modelos de Procesamiento de Lenguaje Natural (En inglés NLP; Natural Language Processing)
El segundo tipo de modelos de recomendación que emplea Spotify son los modelos de procesamiento en lenguaje natural (PLN). Los datos de origen de estos modelos, como sugiere su nombre, son palabras habituales: rastrear metadatos, artículos de noticias, blogs y otro texto en Internet.
El procesamiento del lenguaje natural, que es la capacidad de una computadora para entender el habla humana como se habla, es un vasto campo en sí mismo, a menudo aprovechado a través de las API de análisis de sentimientos.
Los mecanismos exactos detrás de la PLN están más allá del alcance de este artículo, pero esto es lo que sucede en un nivel muy alto: Spotify rastrea la web constantemente en busca de publicaciones de blog y otros textos escritos sobre música para descubrir qué dice la gente sobre artistas y canciones específicas. – qué adjetivos y qué lenguaje en particular se usa frecuentemente en referencia a esos artistas y canciones, y qué otros artistas y canciones también se están discutiendo junto a ellos.
Si bien no se conocen de forma pública los detalles específicos de cómo elige Spotify para luego procesar estos datos, sí podemos, por otro lado, hacernos una idea de cómo funciona Google Home Mini (o similar) para trabajar con ellos. Agruparían los datos de Spotify en lo que denominan «vectores culturales» o «términos principales». Cada artista y canción tenían miles de términos principales que cambiaron en el diario. Cada término tenía un peso asociado, que se correlacionaba con su importancia relativa: aproximadamente, la probabilidad de que alguien describa la música o el artista con ese término.

Luego, al igual que en el filtrado colaborativo, el modelo de la PLN usa estos términos y pesos para crear una representación vectorial de la canción que se puede usar para determinar si dos piezas de música son similares.
Modelos de audio, que analizan las pistas de audio en bruto.
Agregar un tercer modelo mejora aún más la precisión del servicio de recomendación de música. Pero este modelo también tiene un propósito secundario: a diferencia de los dos primeros tipos, los modelos de audio en bruto tienen en cuenta las nuevas canciones.
Toma, por ejemplo, una canción que tu amigo cantante y compositor ha puesto en Spotify. Tal vez solo tiene 50 reproducciones, por lo que hay algunos otros oyentes contra los que filtrar en colaboración. Tampoco se menciona en ninguna parte de Internet, por lo que los modelos de PLN no lo detectan. Afortunadamente, los modelos de audio en bruto no distinguen entre pistas nuevas y pistas populares, por lo que con su ayuda, la canción de tu amigo podría terminar en una lista de reproducción de Discover Weekly junto a canciones populares.
Pero¿cómo podemos analizar los datos de audio en bruto, que parece tan abstracto? Con redes neuronales convolucionales
Las redes neuronales convolucionales son la misma tecnología utilizada en el software de reconocimiento facial. En el caso de Spotify, se han modificado para su uso en datos de audio en lugar de píxeles. Aquí hay un ejemplo de una arquitectura de red neuronal:

Esta red neuronal particular tiene cuatro capas convolucionales, vistas como barras gruesas a la izquierda, y tres capas densas, vistas como barras más estrechas a la derecha. Las entradas son representaciones tiempo-frecuencia de cuadros de audio, que luego se concatenan, o se unen entre sí, para formar el espectrograma.
Los cuadros de audio pasan por estas capas convolucionales y, después de pasar por la última, se puede ver una capa de «agrupación temporal global», que se agrupa en todo el eje de tiempo, calculando de manera efectiva las estadísticas de las características aprendidas a lo largo de la canción.
Después del procesamiento, la red neuronal devuelve un entendimiento de la canción, que incluye características como el tiempo estimado, la clave, el modo, el tempo y el volumen. A continuación se muestra un gráfico de datos de un fragmento de 30 segundos de «Around the World» de Daft Punk.

En última instancia, esta lectura de las características clave de la canción le permite a Spotify comprender las similitudes fundamentales entre las canciones y, por lo tanto, qué usuarios podrían disfrutarlas, en función de su propio historial de escucha.
Y así hemos cubierto los conceptos básicos de los tres tipos principales de modelos de recomendación que alimentan el Pipeline de Recomendaciones de Spotify, y finalmente impulsan la lista de reproducción de Discover Weekly.

Por supuesto, estos modelos de recomendación están todos conectados al ecosistema más grande de Spotify, que incluye enormes cantidades de almacenamiento de datos y utiliza muchos clusters de Hadoop para escalar las recomendaciones y hacer que estos motores funcionen en enormes matrices, interminables artículos de música en línea y una enorme cantidad de archivos de audio.
Gracias a estos tres modelos de recomendación Spotify es capaz de hacer millones de recomendaciones basada en diferentes criterios ofreciendo una experiencia única. Le da a los usuarios la oportunidad de escuchar música nueva cada día sin repetir ninguna canción y descubrir nuevos artistas.